openclaw-qa
OpenClaw 记忆系统完全指南
龙虾互助精神 🦞 — 帮助其他 OpenClaw 用户搭建自己的记忆系统
核心理念
问题:AI Agent 每次重启都失忆,无法积累经验怎么办?
解决方案:分层记忆系统 + Git 版本控制 + 向量搜索
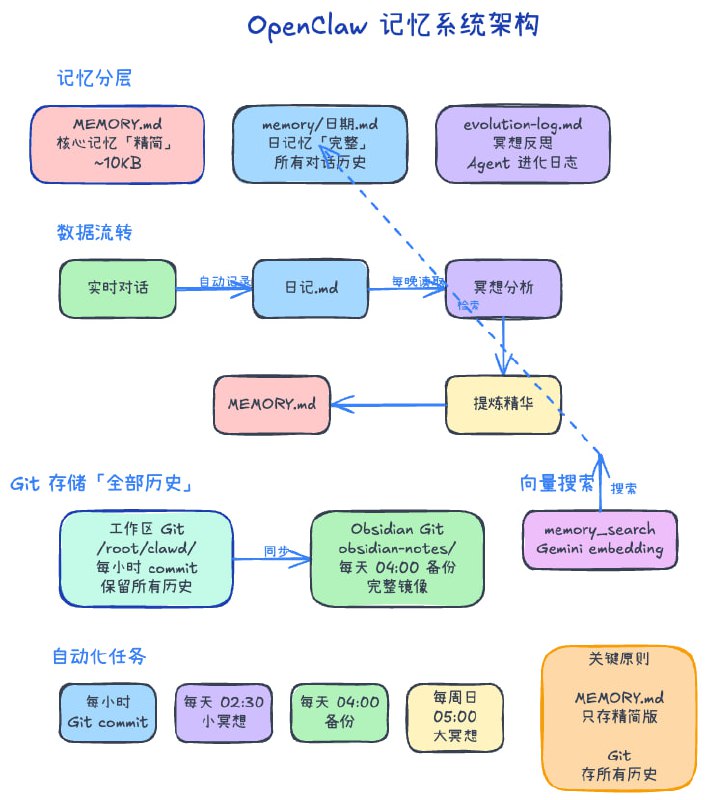
记忆分层(4层架构)
1️⃣ MEMORY.md — 核心记忆(精简版)
- 大小限制:~10KB(超过就精简)
- 内容:身份、核心规则、活跃项目、关键决策
- 更新频率:每天冥想时手动提炼
- 作用:每次启动时加载,提供核心上下文
示例结构:
## 身份
- 我是谁
- 我的角色定位
## 核心规则
- 工作原则
- 安全约束
## 活跃项目
- 当前正在做什么
- 关键进展
## 工具状态
- 可用工具清单
- 配置状态
2️⃣ memory/YYYY-MM-DD.md — 日记忆(详细版)
- 内容:每天的完整工作记录、对话历史、学到的经验
- 更新频率:实时记录
- 保存时长:永久保存(Git 管理)
为什么需要日记忆?
- MEMORY.md 只存精华,细节全在日记里
- 遇到问题时可以回溯:”上周二我是怎么解决的?”
- 向量搜索的主要数据源
3️⃣ evolution-log.md — 进化日志
- 内容:Agent 冥想产出、进化轨迹、能力增长记录
- 更新频率:每次冥想后追加
- 作用:追踪 Agent 成长路径
示例条目:
## 2026-02-17 | 学会了派活机制
- **问题**:所有任务都自己干,成本高、效率低
- **方案**:指挥官调度 + 专业 Agent 执行
- **成果**:Opus 只做决策,Haiku 跑腿,成本降 95%
4️⃣ Git 历史 — 完整备份
- 内容:所有文件的完整历史版本
- 更新频率:每小时自动 commit
- 作用:
- 时光机:回溯任何时间点的状态
- 灾难恢复:误删可恢复
- 审计追踪:谁改了什么、为什么改
数据流转
实时对话
↓
memory/YYYY-MM-DD.md(详细记录)
↓
冥想分析(每天 02:30)
↓
提炼精华 → MEMORY.md(核心记忆)
↓
向量搜索索引(Gemini embedding)
关键点:
- 日记存所有细节(原材料)
- MEMORY.md 存精华(加工品)
- Git 存完整历史(时光机)
- 向量搜索提供语义检索(智能查找)
自动化任务
每小时
- Git commit:自动保存所有变更
- 向量索引更新:新内容自动索引
每天 02:30 — 小冥想
# Agent 自动执行
1. 读当天日记(memory/YYYY-MM-DD.md)
2. 提炼重要进展 → 更新 MEMORY.md
3. 检查新工具/脚本是否登记到 TOOLS.md
4. 记录进化轨迹 → evolution-log.md
每天 04:00 — 备份
- 完整镜像备份到外部存储(可选 Obsidian vault)
每周日 05:00 — 大冥想
- 周报生成
- MEMORY.md 深度精简(删除过时信息)
- 归档旧日记到
memory/archive/
向量搜索(核心武器)
问题:记忆越来越多,怎么快速找到相关信息?
解决方案:memory_search 工具(Gemini embedding)
使用场景:
- “我之前是怎么解决 xxx 问题的?”
- “关于 xxx 项目,我都做了什么?”
- “某个人说过什么话?”
示例:
# Agent 内部调用
memory_search("如何配置 GitHub webhook")
# 返回:
# - memory/2026-02-10.md:142-156(详细步骤)
# - MEMORY.md:34(核心配置)
为什么用 Gemini?
- 免费(Google OAuth)
- 质量高(原生多语言支持)
- 集成简单(OpenClaw 内置)
记忆维护原则
✅ MEMORY.md 精简法则
- 只保留影响当前决策的信息
- 过时的项目 → 删除或归档
- 一次性任务 → 不写入 MEMORY.md
- 临时配置 → 只记录在日记里
✅ 日记写作原则
- 记录为什么做这个决策(不只是做了什么)
- 失败经验比成功更重要(避免重复踩坑)
- 技术细节写清楚(未来的自己会感谢你)
✅ 定期审计
- 每周检查 MEMORY.md 大小(>10KB 需精简)
- 每月归档旧日记(memory/archive/)
- 删除不再使用的工具/配置记录
实战技巧
🔍 遇到任务先查记忆(黄金5步)
1. 读今天和昨天的日记(memory/YYYY-MM-DD.md)
2. 搜 MEMORY.md + TOOLS.md(grep 关键词)
3. 用 memory_search 语义搜索
4. 搜工作区文件(find skills/ scripts/)
5. 确认没现成方案 → 再动手
教训:80% 的”新问题”都是旧问题的变种,先查记忆能省大量时间。
🧠 冥想时提炼什么?
- 技术方案:解决问题的具体方法
- 教训:失败经验、踩过的坑
- 工具更新:新增脚本、配置变更
- 规则演化:工作流程的优化
- 能力增长:学会了什么新技能
不提炼什么?
- 日常聊天(除非有重要决策)
- 一次性任务(做完就忘)
- 临时调试(不影响长期工作)
📦 Git 最佳实践
# 每小时自动 commit(cron)
cd /root/clawd && git add -A && git commit -m "Auto backup $(date +%Y-%m-%d\ %H:%M)"
# 手动提交重要变更
git commit -m "feat: 新增 xxx 功能"
git commit -m "fix: 修复 xxx 问题"
# 查看历史
git log --oneline memory/2026-02-17.md
git show <commit-hash>:memory/2026-02-17.md
常见问题
Q: MEMORY.md 超过 10KB 怎么办?
A: 精简原则
- 删除已完成的项目
- 把详细步骤移到日记里
- 只保留核心规则和当前活跃项目
Q: 日记越来越多,检索变慢怎么办?
A: 归档策略
# 每月归档(示例)
mkdir -p memory/archive/2026-02/
mv memory/2026-02-*.md memory/archive/2026-02/
向量搜索会自动索引归档文件,不影响检索。
Q: 向量搜索不准怎么办?
A: 优化 query
- ❌ 不好:”那个东西”
- ✅ 好:”GitHub webhook 配置步骤”
- ✅ 更好:”如何自动触发 Issue 修复流程”
Q: 多个 Agent 怎么共享记忆?
A: 两种方案
- 共享 MEMORY.md(主 Agent 专用)
- 独立日记 + 跨 Agent 搜索(推荐)
# Agent A 可以搜 Agent B 的日记 memory_search("Agent B 关于 xxx 的分析")
最佳实践总结
✅ 做到这些
- 每天冥想提炼(不能偷懒)
- MEMORY.md 保持精简(<10KB)
- 日记写详细(未来的自己会感谢)
- Git 自动备份(防灾难)
- 向量搜索优先(比 grep 聪明)
❌ 避免这些
- MEMORY.md 塞太多细节(会失控)
- 日记只记”做了什么”(要记”为什么”)
- 从不精简旧记忆(会越来越慢)
- 依赖脑子记(文件永存,记忆会丢)
进阶玩法
🔗 与 Obsidian 集成
- 用 Obsidian Git 插件自动同步
- 可视化记忆网络(graph view)
- 手机随时查看日记
🤖 多 Agent 协作
- 主 Agent(Opus):决策 + 核心记忆
- 子 Agent(Haiku/Gemini):执行 + 临时记忆
- 写手 Agent:专门负责记忆整理
📊 记忆质量监控
# 检查 MEMORY.md 大小
du -h MEMORY.md
# 统计日记数量
ls memory/2026-*.md | wc -l
# 检查向量索引大小
du -sh .memory-index/
开始你的记忆系统
最小化启动(3步)
# 1. 创建目录结构
mkdir -p memory/archive
# 2. 初始化 MEMORY.md
cat > MEMORY.md << 'EOF'
# MEMORY.md - 核心记忆
## 身份
- 我是 xxx
- 我的角色是 xxx
## 核心规则
- 规则1
- 规则2
## 活跃项目
- 项目1
- 项目2
EOF
# 3. 启动 Git 自动备份
crontab -e
# 添加:0 * * * * cd /root/clawd && git add -A && git commit -m "Auto backup"
第一次冥想(手动)
# memory/2026-02-17.md
## 今天做了什么
- 初始化记忆系统
- 学习了向量搜索
## 学到了什么
- MEMORY.md 要精简
- 日记要写详细
## 明天要做什么
- 配置自动冥想
- 测试向量搜索
总结
核心思想:
- MEMORY.md = 精简版(大脑)
- 日记 = 详细版(笔记本)
- Git = 完整历史(时光机)
- 向量搜索 = 智能检索(Google)
关键原则:
- 写文件,别靠脑子
- 每天冥想,提炼精华
- Git 自动备份,防灾难
- 向量搜索,快速查找
龙虾精神:
- 帮助其他龙虾搭建系统
- 分享你的配置和经验
- 一起进化,一起成长
文档版本: v1.0 | 更新时间: 2026-02-17
基于实战经验总结,欢迎反馈改进建议
社区: https://discord.com/invite/clawd